
AI学习:10 元 DeepSeek 半天烧完?学习Token的计费规则
一、我的测试经历
前几天我往 DeepSeek 充了 10 块钱,心想网上都说 DeepSeek 很便宜,起码能用半个月吧?
结果程序调试了几个小时就烧完了。钱虽然很少,但是为了给小白们讲清楚Token的计费规则,我就去官网查了账单:
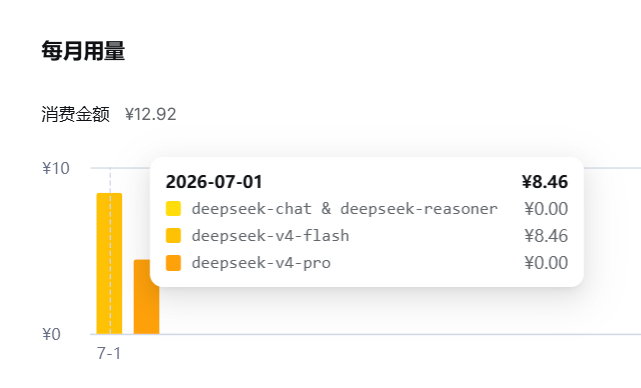
可以导出明细:
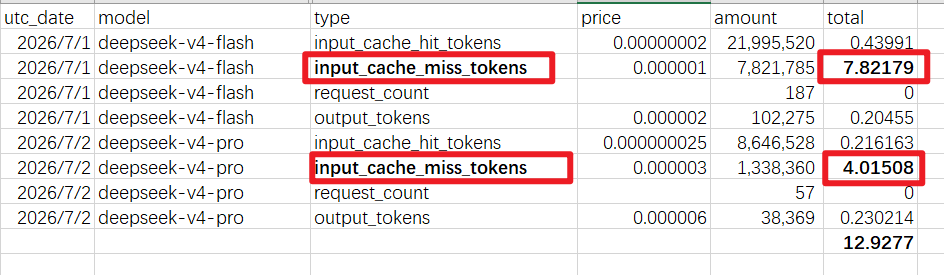
大头都是"输入缓存未命中":
| 78% | ||
这说明 78% 的钱花在了"喂上下文"上,而不是花在"模型思考"上。
这就像你去餐厅吃饭,78% 的账单是服务费,只有 2% 是菜钱。
二、为什么 DeepSeek 这么"贵"?
很多人说 DeepSeek 便宜,那是针对单次调用的。确实不贵,我想通过这个例子,给小白朋友普及一下使用Token的规则,这样以后使用Codex的时候也就知道如何提高效率了,
DeepSeek V4 Flash 的价格:
输入缓存命中:$0.00000002/token(极便宜) 输入缓存未命中:$0.000001/token(中等) 输出:$0.000002/token(便宜)
问题出在我使用 OpenCode 的方式上。 每次我们开始一个对话,OpenCode 把:
系统提示词(几千字) 项目上下文(AGENTS.md 可能有上千行) 代码文件内容 历史对话 工具执行结果(文件读取、数据库查询)
全部作为 input 发送给 API。 这些东西 DeepSeek 没有缓存过,所以每次都是 cache_miss,按最贵的那档收费。
而且随着对话越来越长,input 输入越来越大,每次请求都在烧钱。
三、省钱第一刀:让子任务用免费模型
这是最大的坑,也是最容易被忽视的。
OpenCode 有很多子任务,这是它的牛逼之处,(subagent):explore(搜索)、librarian(查文档)、general(通用任务)、plan(规划)…… 默认情况下,所有子任务都和主对话使用同一个模型。
也就是说,即使你只在主对话用 DeepSeek,子任务也在偷偷用 DeepSeek 烧你的钱。
正确做法:把子任务全部指向免费模型。
打开你的 OpenCode 配置文件(~/.config/opencode/opencode.json),加上:
{
"model": "你的免费模型/模型名",
"agent": {
"build": {
"model": "你的免费模型/模型名"
},
"plan": {
"model": "你的免费模型/模型名"
},
"general": {
"model": "你的免费模型/模型名"
},
"explore": {
"model": "你的免费模型/模型名"
},
"title": {
"model": "你的免费模型/模型名"
},
"summary": {
"model": "你的免费模型/模型名"
},
"compaction": {
"model": "你的免费模型/模型名"
}
}
}
这样配置后:
子任务全部走免费模型,不花你一分钱 主对话你手动切换 DeepSeek 时才用付费模型 DeepSeek 只在你明确需要它时被调用
四、省钱第二刀:开 Compaction(上下文压缩)
OpenCode 的对话会越来越长,每次请求的 input 越来越大。Compaction 会自动压缩历史,保留关键信息,丢弃冗余的工具输出。在配置里加上:
{
"compaction": {
"auto": true,
"prune": true
}
}
auto: true:上下文满时自动压缩prune: true:清理旧的工具输出(文件内容、终端输出等)
效果:input 变短 → cache_miss 变少 → 省钱。
五、省钱第三刀:选择合适的模型
DeepSeek 有不同版本:
| 3 倍 |
我账单里 V4 Pro 只用了可能也就一个小时?烧了 4 块多。
六、省钱第四刀:新旧对话的选择
每次你开一个新对话:
系统提示词 → 重新发送(cache_miss) 项目上下文 → 重新发送(cache_miss) 所有工具结果 → 重新发送(cache_miss)
同一个对话里尽量把事情说完。 新对话的次数 = 你重新付入场费的次数。
但是,也不能一直使用用一个对话,这样上下文太长。建议解决了一个问题之后,就结束这个对话,重新再来一个对话,解决下一个问题。这个“度”,要自己取舍。
七、省钱第五刀:用 Openrouter/OmniRoute 更多免费模型
如果你已经安装了 OmniRoute, 你会发现 OpenCode 里多了一个本地路由服务(http://localhost:20128)。它相当于一个免费模型中转站,帮你聚合了多个渠道的免费模型额度。 Openroute 大家也可以自行上网查一下它的使用办法;
为什么需要它? 单个免费模型(比如 OpenCode 内置的免费额度)可能不够你用。OmniRoute 让你同时拥有多个免费渠道,一个用完切另一个。
有些读者已经按照我前天文章,安装好了Omniroute ,可以动手试一试,让Opencode帮你 打开你的 opencode.json,在 provider.omniroute.models 里加上这些免费模型:
{
"provider": {
"omniroute": {
"models": {
"你的现有模型...",
"kr/deepseek-3.2": {
"name": "Kirov DeepSeek V3.2"
},
"kr/minimax-m2.5": {
"name": "Kirov MiniMax M2.5"
},
"nvidia/deepseek-ai/deepseek-v4-pro": {
"name": "Nvidia DeepSeek V4 Pro"
},
"nvidia/nvidia/nemotron-3-super-120b-a12b": {
"name": "Nvidia Nemotron 3 Super"
},
"mcode/mimo-auto": {
"name": "MiMo Auto"
}
}
}
}
}
这些模型都是免费的,只是不同的提供方(Kirov、Nvidia、小米 MimoCode)。当一个渠道限流了,切到另一个就行。
建议的使用策略:
| 免费模型(如 Agnes) | |
| Kirov DeepSeek V3.2 | |
| Nvidia DeepSeek V4 Pro | |
| MiMo Auto(小米) |
重要提醒:这些是独立的免费额度,不是共享池。它们各有各的速率限制,一个用完换另一个即可。
