基金套利-AI编程实战篇-3
 好饭不怕晚,继续磨刀ing.
好饭不怕晚,继续磨刀ing.

 有这个毅力,没有做不成的事情
有这个毅力,没有做不成的事情

✅ 完成核心重构 (纯 SQLite 架构与数据链路健壮性)
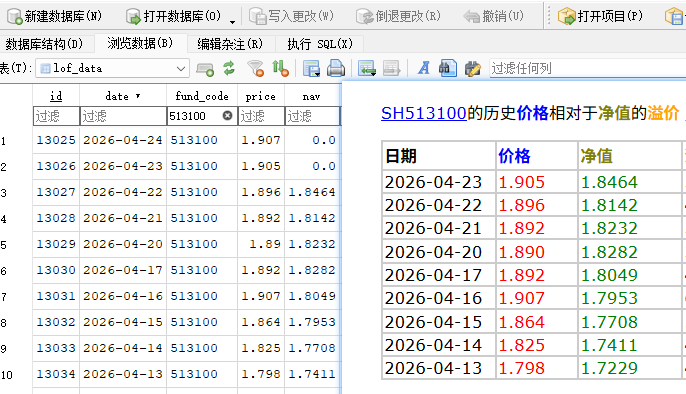
在迭代中彻底抛弃了脆弱的 CSV 文件存储,全面拥抱 SQLite 关系型数据库,并对数据大一统采集、官方估值计算和监控页面进行了深度修复与重构。
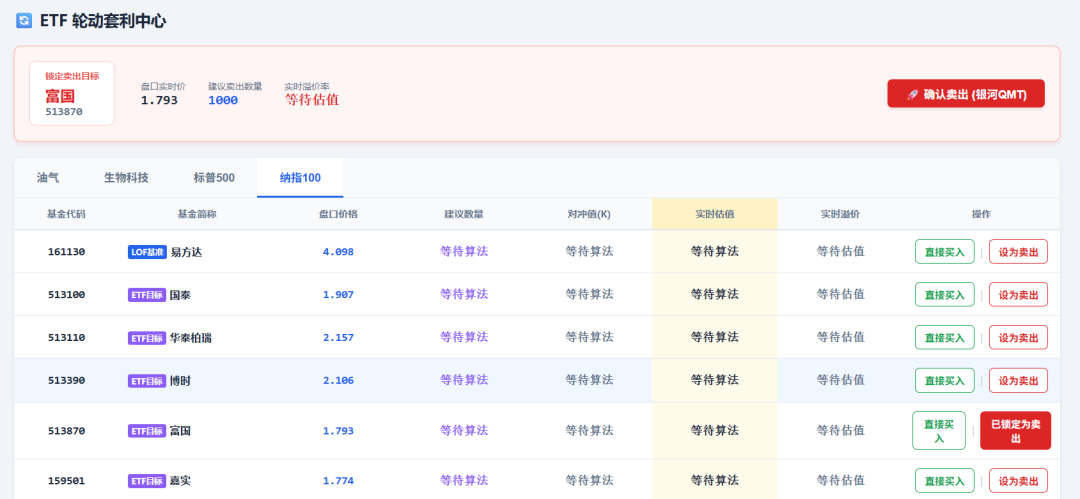
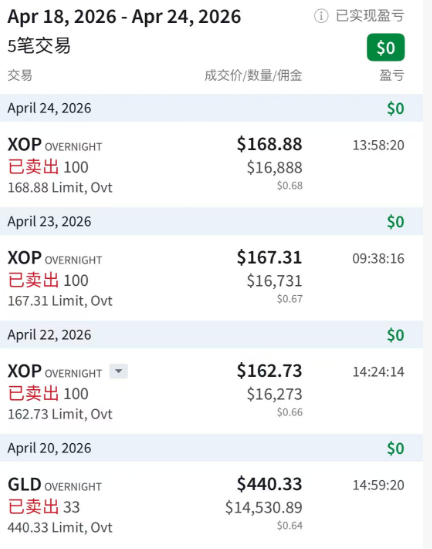
✅ 阶段性里程碑:估值双引擎下沉 ArbCore,全面跨入后台智驾时代,准备开启轮动套利
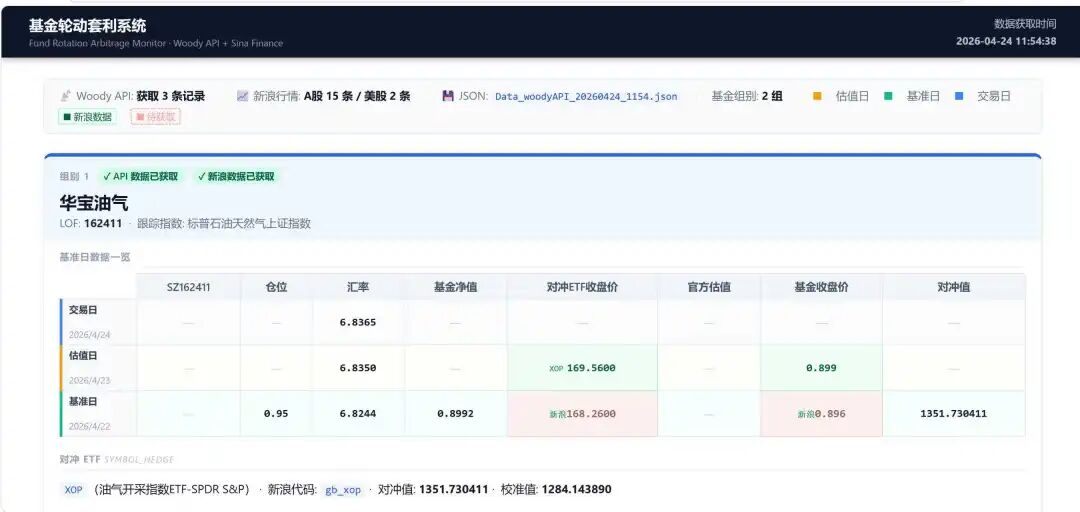
底层数据抓取具有极高健壮性与防刷机制。静态推演与动态盘中推演的核心算法已全部剥离为独立微服务模块,寄宿在 arbcore基座中。
✅ 静态官方估值引擎 (Static Valuation) 独立封装
新建独立函数库,接管了原来庞大的 pandas 矩阵推演计算逻辑。
✅ 极速动态估值引擎 (Dynamic Valuation) 诞生
新建实时估值库,专为后台无人值守环境打造。 **引入内存级缓存 (Memory Cache)**:在盘中首次调用时查询 SQLite 获取 T-1完美基座数据并驻留内存。后续面对每秒数次的 Tick 级实时汇率、实时 ETF/期货跳动,实现 毫秒级极速推演,彻底告别 IO 瓶颈。
✅ 工作流简化为四步流水线
拉取 API 数据湖->提取核心因子入库->抓取市场数据->抓取基金 收盘价/净值。全面拥抱 SQLite 持久化,所有脏活累活收口到数据库管理接口

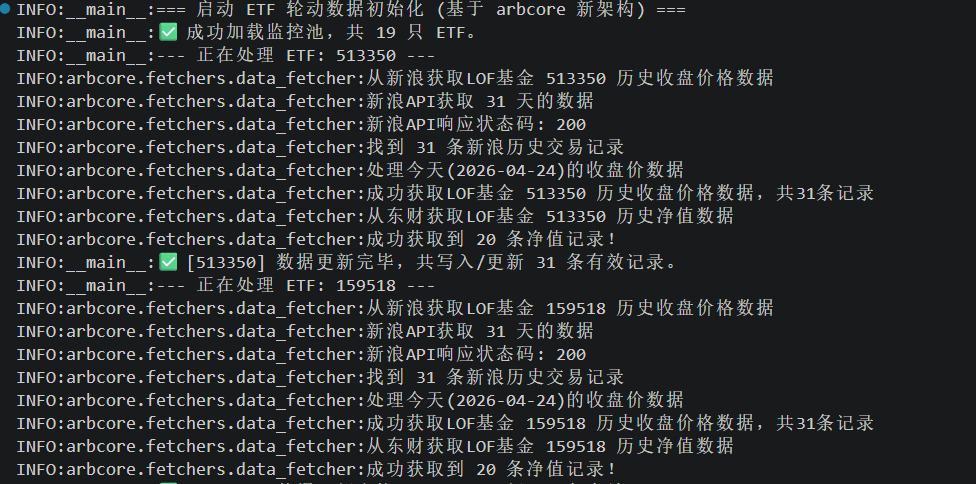
 正确无误 这下子,有了"轮动套利"的基础
正确无误 这下子,有了"轮动套利"的基础