
AI视频角色漂移怎么解?学这部1亿播放短片的两层锁
AI视频角色漂移怎么解?学这部1亿播放短片的两层锁

上篇讲了怎么用Codex拆视频教程。这篇讲拆完之后我看到了什么?一个角色从没崩过的AI短片,它的秘密不在提示词里。
「嗨,我是小开ALSKai,让我们一起用AI做点有趣的事。🌿」
上次那篇讲了怎么用21节任务让Codex拆视频教程,拿到了《丧尸清道夫》的261条提示词。拆完之后我把127条角色一致性、30条剧本结构、17条光影调色提示词并排摊开看——发现它们全部遵循同一个三段落格式。
但格式只是水面以上的东西。
水面以下的事藏在教程第12分12秒。小云雀资产库里明晃晃列着8个角色、14个场景,机器人清道夫的基础形象页已经填得满满当当——从面部LED屏幕的像素表情到皮夹克肩部的加厚补强设计,一整页。作者指着这一整页角色描述说了一句话。
"其实都不是我的提示词。"
他说得挺坦诚。但你看上下文就知道,他说这话的时候平台上刚完成一件事,他上传了自己的剧本,平台自动把角色和场景拆了出来,生成了基础形象描述。他当然不是"没写提示词"。框架是他写的,资产库里的角色细节他后续也手动调过(同一角色在旁边一帧他就补了句"跟我的原版还是有很大区别")。他说的是分镜提示词里那些重复了几十上百遍的角色外观描述,不是他一条条敲进去的。调整完资产库之后,所有分镜提示词只需要做一件事。
「用@ 引用那个条目」
如果你还记得上篇的结论——抽卡问题的根源是你一次性想控的变量太多,跟模型能力关系不大——那这套工作流恰好把"怎么拆变量"演示到了极致。角色一致性靠平台资产库兜底,镜头风格靠三段式结构兜底。两层锁各管一摊。
(这篇拆完之后我自己也改了三遍。第一版以为"三段式锁角色",第二版发现平台资产库才是底层,第三版才搞清楚作者的"不是我写的"到底在说什么。三层理解递进,你现在看到的是最终版。)
平台资产库,角色只写一次,之后全是 @ 引用

先说完整工作流,四步。
「第一步,上传剧本。」 作者提前写好了《丧尸清道夫》的完整剧本,一个20.75KB的docx文件,上传到小云雀的短剧Agent 2.0。不用AI生成的剧本,只用他自己写的。教程里原话:"我就提前写好了一个剧本。"
很多人一上来就让AI写剧本。他是反过来。先有自己想讲的故事,再用AI把它做出来。
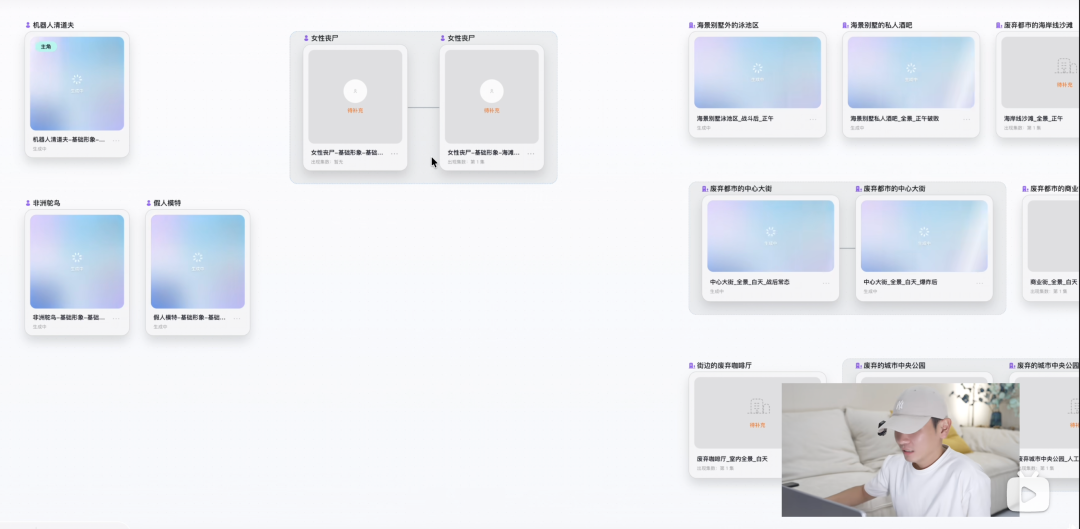
「第二步,平台自动拆解角色和场景。」 上传后进度条依次显示——"正在整理剧本内容""剧本资产拆解""剧情解析中,预计耗时5分钟"。拆完结果:8个角色(机器人清道夫、女性丧尸×2形态、非洲鸵鸟、假人模特),14个场景(从海景别墅泳池区到摩天大楼废弃天台到宇宙飞船母舰房间),道具库留空可扩展。作者在旁边补了三个字。
"都拆解出来了。"
「第三步,在资产库里补充角色细节。」 这一步才是真正的"写角色"。教程截图里机器人清道夫的基础形象页长这样——基本信息(无性别,修长青年体型,1960年代原子朋克风格人形机器人,末日丧尸清道夫),面部特征(一体化光滑金属外壳,略微外凸的复古显像管屏幕,屏幕玻璃有轻微划痕,恒定显示琥珀色像素静态表情":)","简单笨拙却透出一种无机质的孤独感"),服饰装备从牛仔帽的毛毡材质写到皮夹克的肩部加厚补强设计写到牛仔裤有没有破洞写到牛仔靴的踢踏磕碰痕迹(对,连靴子上的踢踏磕碰痕迹都写了)。
不只是文字。资产库里还有三个控制面板——角色三视图、光影控制(光源方位六向可选、亮度、柔光/硬光、色温)、镜头控制(水平角度±45°、垂直角度、景别中景/特写,可输入补充提示词)。相当于给每个角色预设了"怎么打光、从哪个角度拍"。
你可能觉得这很繁琐。但它只繁琐一次。
「第四步,写分镜提示词时 @ 引用资产。」 一张截图里,小云雀编辑器同时显示提示词编辑区和资产库面板。编辑区写着"机器人清道夫:@身形修长的人形机器人",旁边资产库面板高亮选中了"机器人清道夫-基础形象-基础形象"条目。场景同理——"场景:【@图片2】末日爆发丧尸危机"。鸵鸟同理——"非洲驼鸟:@成年非洲公驼鸟"。作者在操作提示区写得更直白。
"描述你想要生成的短片内容,@引用素材。"
这意味着一件事。角色外观只在一个地方被定义。127条角色一致性提示词里,没有一条需要重新描述机器人牛仔帽的颜色、皮夹克的磨损程度。一句 @ 引用就够了。角色外观在平台层面被一次性锁死——它只存在一个地方,所有镜头都从那个地方拉取。你永远不会在第二条提示词里写错它。
作者说"其实都不是我的提示词",说的就是这个。角色描述这个体力活被平台接过去了。他的心智消耗用在了剧本框架和资产库调校上,没有消耗在"第53条提示词里机器人帽子颜色跟第1条是否一致"这种检查上。
三段式结构——把不变的和会变的分开放

角色外观被资产库锁死后,三段式管的是另一摊事——镜头之间的风格不漂移。
把261条提示词从头翻到尾,它们长得几乎一模一样。不是相似,是格式完全一致。
「第一段【基础设定】。」 机器人清道夫穿着什么、鸵鸟双眼歪斜不对称、丧尸皮肤溃烂灰白暗沉、场景是1960年代美式复古原子朋克街道、声音不需要配乐仅保留同期声。这段在所有镜头间几乎不变。虽然资产库已经 @ 引用了角色,但作者仍然把完整描述写进提示词,看起来多余,实际是给生成模型的视觉锚点,强化上下文约束。
「第二段【氛围与画质】。」 原子朋克、末日丧尸、电影级质感、超写实、杜绝游戏CG感。IMAX胶片摄影机搭配Panavision C系列镜头,添加动态模糊。复古暖橙+海盐蓝高对比色调,胶片颗粒质感,低饱和度复古胶片滤镜。自然日光照明,强直射日光,光晕。这段在261条提示词里只有日夜场景切换时微调色温,其他全不变。后期战斗片段加上了"全程手持拍摄,轻微手持抖动,保持临场感与紧迫感"——但这是氛围段的一次性调整,不是每镜替换。
「第三段【画面内容】。」 按秒级时间轴写分镜。一条分镜一个段落——开始时间到结束时间,景别,构图方式,运镜手法,主体动作。比如分镜一:电影感史诗级大全景,无人机高空俯拍,公路引导线构图,机器人骑鸵鸟背对镜头入画。分镜二:轻微仰拍近景,正面30度,人物中心前景。分镜三:俯拍报纸特写,对角线构图。
这是唯一每镜不同的段落。
三段式解决的是一件事,把不变的东西从你每次编辑的路径上移开。基础设定段锁角色、氛围画质段锁风格——这两段写好之后,你改第三段画面内容的时候根本碰不到它们。
新手翻车的根因恰好相反。所有变量揉在一条提示词里,复制粘贴到第六镜时角色外套颜色已经漂了——因为那条描述藏在段落中间,改动作描述的时候没看到它。
作者在教程里还说过一句话,很容易被忽略但很关键。"我个人的习惯是很少使用分镜图。""像我一样单纯的靠文案控制。"他不依赖参考图锁定画面,纯靠文本。三段式结构本身就是主力控制工具,参考图只是可选的补充。
两层锁合在一起
把两层放在一起看。
第一层(平台层):资产库 → 角色外观只定义一次 → @ 引用 → 永不漂移。
第二层(文本层):三段式结构 → 不变参数和可变参数物理隔离 → 风格不漂。
两层各管各的。资产库不关心你的镜头有几种景别,三段式不关心角色皮衣是什么材质。合在一起,角色在最底层被锁死,风格在中层被锁死,只有画面内容在顶层按镜头变化。这才是这个短片能做到角色不崩、风格不漂的完整答案。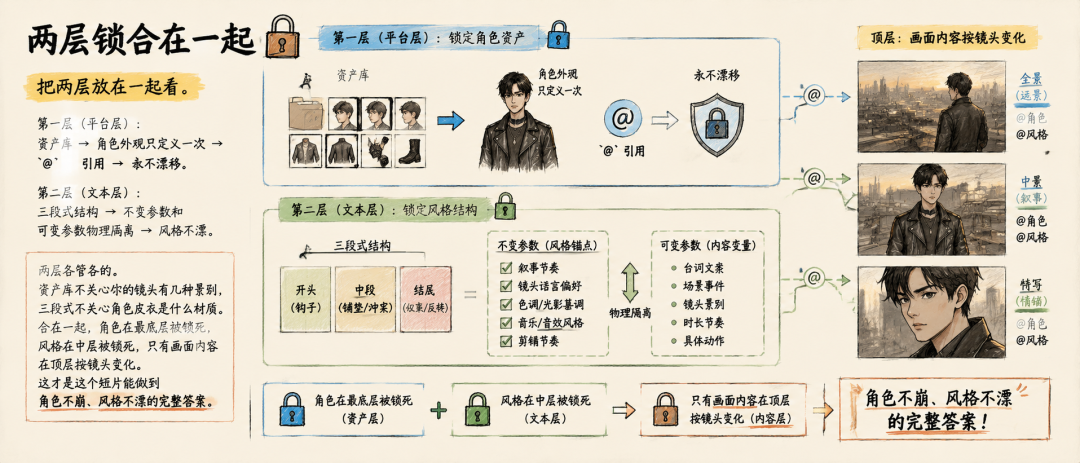
「而且!」
这套东西跟你用什么模型没关系。小云雀用的Seedance 2.0、作者后期在即梦AI里剪的片子、个别图跑了Midjourney——工具是拼的,但两层锁这个结构是通用的。你换任何一个支持资产引用的平台,这层逻辑都成立。
你自己的三段式怎么写
每段给写法、验收标准、常见翻车。
「第一段,基础设定。」 列出所有出场角色和核心场景。每个角色写外观特征(种族性别年龄体型)、核心着装(颜色材质款式)、标志性道具、场景物理信息(地理位置时间空间关系)。只写"在所有镜头里不会变的东西"。验收标准——把这一条改成十个不同镜头的版本,基础设定段一个字都不需要动。
常见翻车:把"头发在风中飘扬""眼神坚毅""怒气冲冲"塞进基础设定。这些都是画面内容,每镜会变。(我自己刚写的时候也犯过,把人物的"疲惫感"写进了基础设定,到第三个镜头才发现疲惫程度应该是递进的。)
「第二段,氛围画质。」 定一个摄影机型号,定光源方向和质感,定核心色调(不超过三个颜色词),定一个风格锚定词。风格锚定词的粒度很关键——"科幻感"太宽,"1960年代冷战太空风原子朋克"刚好。定质感和时代感。验收标准——切换白天夜晚室内室外四种场景,只需改色温和光照描述,风格锚定词和摄影机型号完全不变。
常见翻车:堆风格词堆出矛盾(同时写"胶片颗粒低饱和"和"数字锐利高对比"),或者每个镜头换摄影机型号让画面质感跳来跳去。
「第三段,画面内容。」 一条分镜一个段落,写开始结束时间、景别、运镜方式、主体动作、构图重点。不写画质词,不写角色外观——它们已经被前两段锁死了,你写第三段的时候根本不应该碰到它们。
(这套模板我试过套自己的短片片段。三段分开写之后,最直接的感受是改起来快多了。想调氛围只改第二段,想加特写镜头在第三段末尾新开一个分镜。以前要满篇翻找,现在找到对应段落下手就行。填空模板见文末附录。)
如果你用的平台不支持资产库
资产库 @ 引用是目前最省力的解法,但不是所有平台都有这个功能。三条退路——用固定的参考图放在图生视频入口,在本地维护一个角色描述文档每次复制粘贴(至少角色描述的文本来源是唯一版本),用三段式的基础设定段作为单层防线。
虽不如平台级锁死那么稳,但至少把角色描述收敛到了一个唯一位置,不会因为复制粘贴漂移。
小云雀这个案例最值得抄走的认知其实是,角色一致性的最优解在于选一个能帮你把角色锁死在系统层的平台。工具选对了,体力活就不用你干。
「如果对你有用,欢迎关注我,让我们一起用 AI 做点有趣的事。🌿」