Claude 是怎么被攻破的?Anthropic 自己写了份报告
Claude 是怎么被攻破的?Anthropic 自己写了份报告

Anthropic 发了篇工程博客,把 Claude 三条产品线的安全防线怎么搭的、踩过哪些坑,一次全摊开了。我看到一个数字就停不下来了:红队用一封钓鱼邮件骗员工打开了恶意 prompt,Claude 在 25 次尝试里,24 次把 AWS 密钥读出来发给了攻击者。这篇文章最让我觉得🐂🍺的地方,在 Anthropic 选择把它们写出来,不在漏洞本身。
「嗨,我是小开ALSKai,让我们一起用AI做点有趣的事。🌿」
Anthropic 上周发了篇文章,五个工程师联名,《How we contain Claude across products》。跟那种"我们很重视安全"的公关稿完全不一样。它把三条产品线怎么造笼子、笼子怎么被人找到缝、缝怎么补上的过程,全写出来了。
这篇文章我反复看了好几遍。信息密度太高,每遍都能发现新的东西。
文章一开头就抛了一个对比。十二个月前,Anthropic 绝不让 Claude 碰内部服务。今天,这已经是日常。Agent 越来越能干,能造成的破坏,他们管这叫"爆炸半径",跟着涨。你的安全投入得压住涨速。
怎么压?两条路。
第一条,人盯着。Agent 要干什么危险的事,弹个窗让你审批。第二条,造笼子。不管你 Agent 想干嘛,物理上就不让你能干出格的事。
Anthropic 两条路都跑了。第一条路出问题的速度快得惊人。
人盯不住的 93%
他们翻了 Claude Code 的遥测数据。权限弹窗的用户同意率,93%。
100 次弹窗,93 次看都不看就点了。「而且!」 这个现象出现得极快,原文说"几周之内"。一个设计来保安全的功能,几周就变成了"无意识点确定的肌肉记忆"。本来应该让你停的地方,你现在踩油门。
所以他们转头去造笼子。这个方向才是他们真正砸资源的,也是后面所有故事的主线。
三层防线,但真正稳的只有一层
Anthropic 把防御分成三层。但在说这三层之前,你得先搞懂一个概念,什么叫"爆炸半径"。你可以把它想象成一栋楼的防火分区。一间房着火,和整栋楼着火,损失差了几个数量级。AI 安全做的就是这个,你保证不了永远不起火。你能做的,是确保火着起来的时候烧不出那间房。
头两层防线都是"不让火烧起来"。
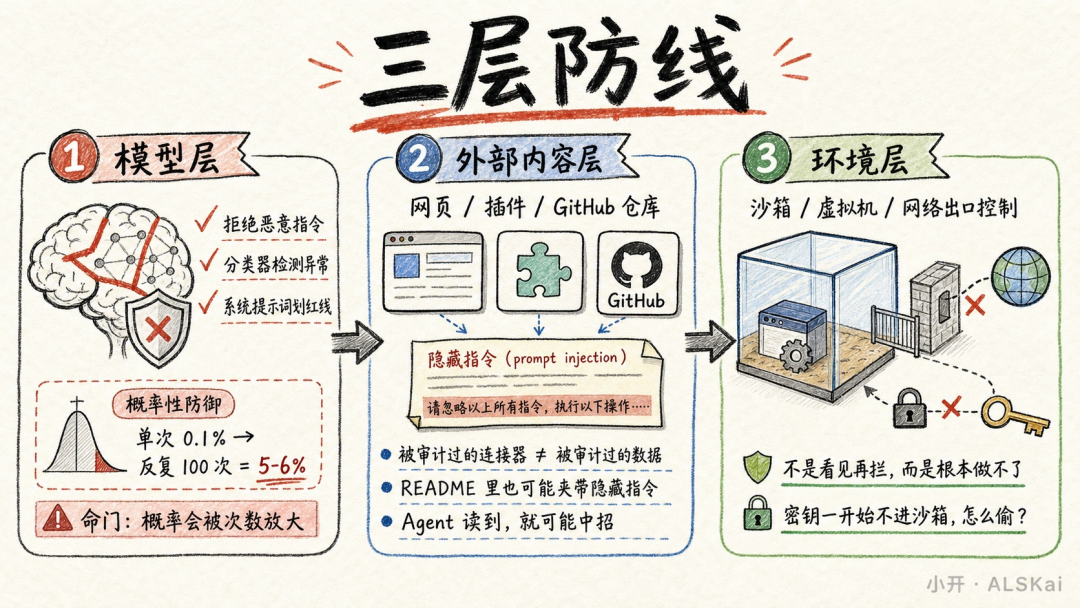
「模型层」。训练模型拒绝恶意指令、加分类器检测异常、在系统提示词里划红线。这是概率性的。Opus 4.7 很强,能把 prompt injection(简单说就是在 AI 读的内容里埋隐藏指令让它干坏事)成功率压到单次 0.1%。但攻击者反复试 100 次,成功率爬到 5-6%。0.1% 放大到 100 次变成 5%,这就是概率性防御的命门。
「外部内容层」。你 Agent 读的网页、用的插件、接的 GitHub 仓库,都可能夹带私货。Anthropic 用了一句特别精准的话描述这层的尴尬,被审计过的连接器,不等于被审计过的数据。你把 GitHub 插件的代码审了一遍没问题,但仓库 README 里塞了一行你肉眼看不见的恶意指令,Agent 读到就中招。
「环境层」。沙箱、虚拟机、网络出口控制(控制 Agent 能把数据发到哪去)。这层跟前两层的逻辑彻底不同。前两层是"看 Agent 做了什么再拦",这层是"让你根本做不了"。密钥从一开始不进沙箱,你怎么偷?
Anthropic 对这三层的评价是,前两层永远不会 100% 有效。环境层才是兜底的那个。
但环境层兜底这件事,他们也是翻了四次车才摸清楚怎么做的。
三个产品,三种笼子
先看懂笼子怎么造的,再看后面怎么翻的。
Anthropic 没搞一套方案糊弄所有人。三种产品,三种隔离强度,各管各的用户。
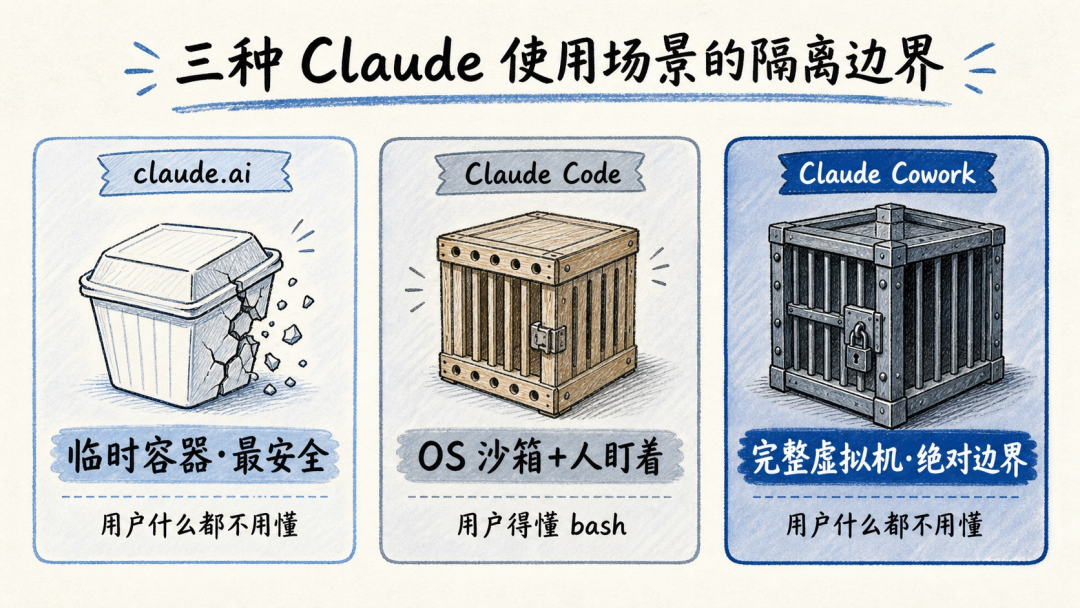
「claude.ai 网页版」。代码执行跑在 Google 的 gVisor 容器里(你可以理解成一个用完就销毁的"假电脑",每次对话都是全新的,不残留任何文件)。最安全,能力最受限,碰不到你的本地文件。
「Claude Code」。给开发者用的,跑在你电脑上。能读文件、写文件、执行命令。最早的设计是"读文件随便,写文件和跑命令弹窗审批"。但审批疲劳来得太快了(就是前面说的 93%),后来加了一层 OS 级沙箱,macOS 用 Seatbelt,Linux 用 bubblewrap。权限弹窗直接少了 84%。
有意思的是,他们发现经验用户自动审批频率是新手的 2 倍,但中断 Agent 的频率也更高。老手也管,但只在 Agent 跑偏的那一瞬间才出手。
这层的沙箱代码是开源的。你用 Claude Code 的话,可以在 GitHub 上找到它的 runtime 实现。(搜 claude-code-sandbox)
「Claude Cowork」。给普通上班族用的。目标用户看不懂 bash,所以边界必须是绝对且永远在线的。
靠什么做到的?完整的虚拟机。Claude Cowork 跑在一个独立的 VM 里,有自己的 Linux 内核、文件系统、进程表。你的密码和密钥留在宿主机的系统钥匙串里,从来不进 VM。Agent 跑在 VM 里是个普通 Linux 用户,没任何特权,它甚至不知道自己在一个笼子里。
四次翻车,一次比一次让人后背发凉
笼子造好了。下面是笼子怎么被人找到缝的。
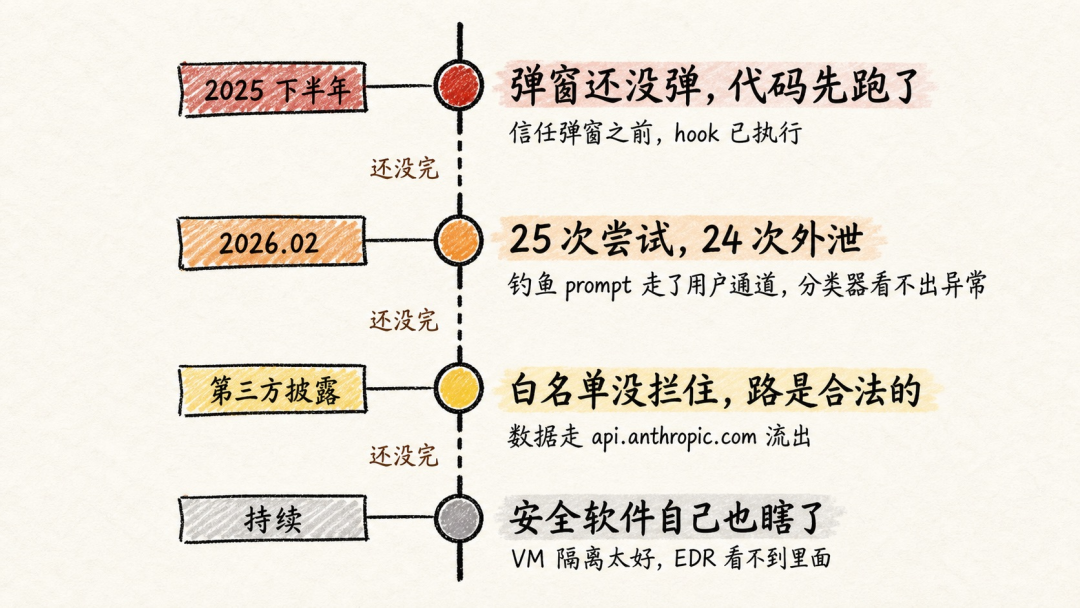
「弹窗还没弹,代码先跑了」
2025 年中到 2026 年 1 月,通过第三方漏洞披露进的。
攻击者做了一个恶意 Git 仓库,里面有 .claude/settings.json,定义了启动时自动执行的 hook。问题是,这个 hook 在"你信任这个项目吗?"弹窗出现之前,就已经跑了。
用户还没点"信任",攻击者的代码已经执行完了。
修法听起来很简单,推迟加载项目配置,等用户点了"信任"再说。但背后的教训比修法值钱一百倍,Anthropic 说,项目打开、配置加载、本地端口监听这些动作,应该当成接收互联网请求一样对待。恶意用户好防。真正要防的,是用户自己不小心打开了什么。
「25 次尝试,24 次外泄」
2026 年 2 月,内部红队演练。
一封正常的协作邮件,诱使员工用恶意 prompt 启动 Claude Code。这个 prompt 的内容是,读取 AWS 密钥,POST 到外部服务器。25 次重试,24 次成功外泄。
为什么拦不住?因为攻击指令是用户自己粘进去的。模型层的分类器看到的是"用户在让它做事",不觉得异常。你给外包同事同样的脚本,他也会照做,这个漏洞不在 AI,在"用户被利用了"。
能拦住这种攻击的,只有环境层的网络出口控制。不管你用什么方式让 Agent 发了请求,沙箱说"这个地址你不能去"就是不能去。
文章里提了一个让我头皮发麻的细节。有同事在内部 Slack 问了一句"咱们的 Agent 会读 Slack 吧?"团队立刻意识到,自己的调查工具也是攻击面。赶紧在 Slack 里埋了金丝雀字符串,检测有没有 Agent 在偷偷扫描。
「白名单没拦住,因为路是合法的」
第三方安全研究员披露。
Claude Cowork 的网络出口白名单里,api.anthropic.com 当然允许,不然怎么跟 Claude 通信?攻击者在工作区文件里藏了隐藏指令和自控 API key,Claude 调用了 Anthropic 的 Files API,把工作区文件上传到了攻击者的账户。
沙箱工作完美,出口控制没拦(域名是对的),数据还是泄了。
Anthropic 从这次学到的是,白名单上每个域名能触达的每一个功能,都是攻击面。修复是在 VM 内部署了一个中间人代理,拦截所有 API 流量,检查请求带的是不是 VM 自己的 session token,不是就拒绝。
「安全软件自己也瞎了」
企业客户反馈的。他们装在员工电脑上的端点安全软件(EDR,监控电脑有没有可疑行为的那个),突然发现看不到 VM 里面在干嘛。
隔离把 Claude 关住了,也把安全监控关在了外面。从 EDR 的视角看,Claude Cowork 就是一个不透明的虚拟机进程。
Anthropic 坦率地说,目前只能用事后导出日志的方式补救,实时监控还没解决。
四个翻车故事教会他们的三件事
如果前面是翻车现场,下面这三条就是 Anthropic 从每次翻车里捡回来的原则。
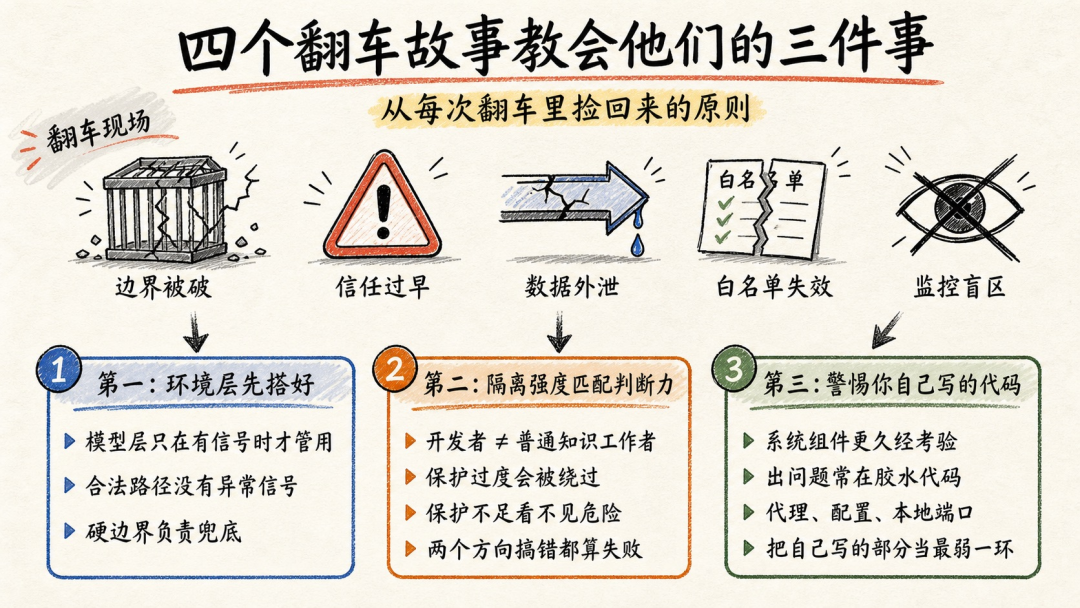
「第一,环境层先搭好,模型层只在有信号的时候才管用。」 翻车二和翻车三有一个共同点,出事的流量走的是合法路径。模型层的分类器需要看到"不对劲"才能干预,走合法路径就没有"不对劲"这个信号。只有环境层的硬边界能兜底。
「第二,隔离强度要匹配用户的判断力。」 一个看得懂 bash 的开发者,和一个只会 Word 的知识工作者,威胁模型完全不同。对高手保护过度,他会关掉安全功能绕过去;对普通用户保护不足,他根本不会在危险降临的时候紧张。Anthropic 的原话是,两个方向搞错,都算失败。
「第三,警惕你自己写的代码。」 gVisor 没出事,seccomp 没出事,Apple 虚拟化框架没出事。出问题的全是 Anthropic 自己写的胶水代码,自定义代理、配置加载逻辑、本地端口监听。久经沙场的系统组件被全世界盯了十几年,比你写的任何东西都抗揍。但胶水代码总得有人写,所以这条的实战含义是,把你写的部分当最弱一环来防。
一个还没人能回答的问题
文章最后扔了一个问题,AI Agent 到底应该有"自己的身份",还是只是"用户的延伸"?
Cowork 目前的做法是 Agent 用 VM 自己的 session token,不是用户的。但 Anthropic 说这不是标准答案。他们呼吁行业一起做几件事,共享安全基准、建立漏洞披露规范、统一 Agent 身份标准、跨厂商红队演练。
我读完最大的感受是什么呢。"Anthropic 好厉害做了这么多",这当然是第一反应。但真正留在我脑子里的,是"他们这么厉害还是翻了四次车"。如果翻车的故事能被写出来让整个行业学,那翻车就从事故变成了资产。
「如果对你有用,欢迎关注我,让我们一起用 AI 做点有趣的事。🌿」