我写了个工具,它能够永久保存公众号文章(保姆级教程)
我写了个工具,它能够永久保存公众号文章(保姆级教程)

用一张 Excel 表格,把你收藏过的公众号文章批量保存成本地 Markdown,搭好只要 15 分钟。
「嗨,我是小开ALSKai,让我们一起用AI做点有趣的事。🌿」
这篇文章介绍的工具,是我自己写的。
它叫 wechat-notebank,一条命令行工具。把公众号文章链接丢给它,它就帮你存成本地 Markdown 文件,带标题、作者、发布日期。想要的时候打开文件夹就行,不用再去收藏夹里翻十分钟。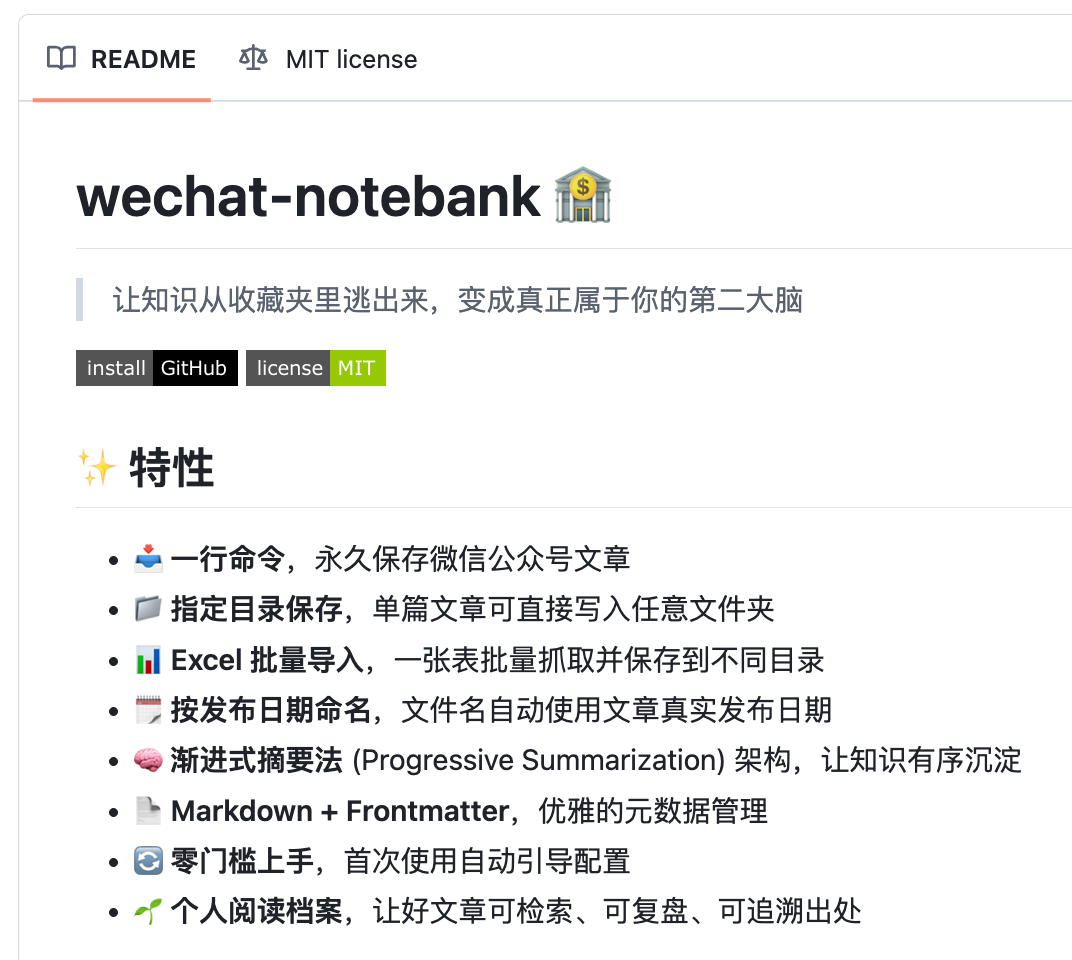
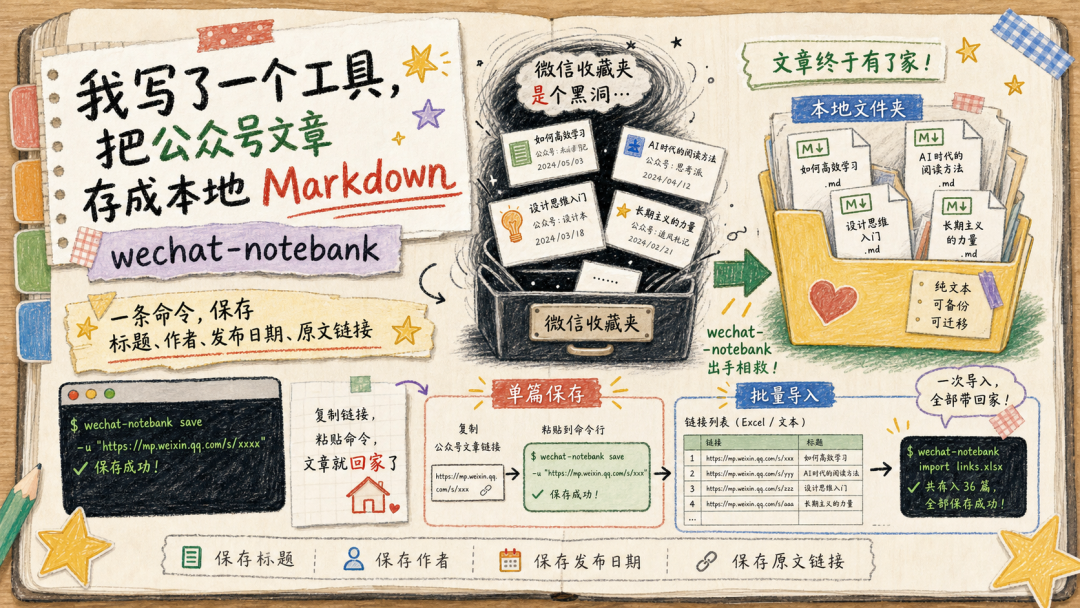
为什么要做这个?因为微信收藏夹是个黑洞,文章进去容易,出来很难。你下次写东西的时候想起"之前看过一篇特别好的",翻十分钟找不到,最后放弃。(对,就是那种"它明明属于我,但我够不到"的感觉)
我把这件事解决成了一条命令,叫 wechat-notebank。它做的事很简单,把公众号文章保存成 Markdown 文件,带标题、作者、发布日期、原文链接。单篇保存只是开胃菜。真正解决问题的是批量导入,把十几篇文章的链接填进一张表格,一条命令全部存好。
这篇文章带你从安装到批量导入,一步步走完。需要一点点命令行,但我会把每条命令都写出来,你复制粘贴就行。
「好,废话不多说,我们开始!」
装好它,先确认能跑
wechat-notebank 目前还没发布到 npm registry,直接 npm install -g wechat-notebank 会报 404。这不是你电脑坏了,是我的包还没正式发。(我会尽快更新的!)
如果你不想自己敲命令,直接把仓库地址丢给 Claude Code 或 ChatGPT,说"帮我装一下",它会替你跑完。
当前推荐从 GitHub 装:
npm install -g https://github.com/Albert-Lsk/wechat-notebank/archive/refs/heads/main.tar.gz装之前确认两件事,电脑里有 Node.js 和 Chrome。Node.js 负责跑命令,Chrome 负责打开公众号页面、把内容抓出来。(微信公众号不是普通静态网页,必须有真实浏览器渲染)
装完跑一下:
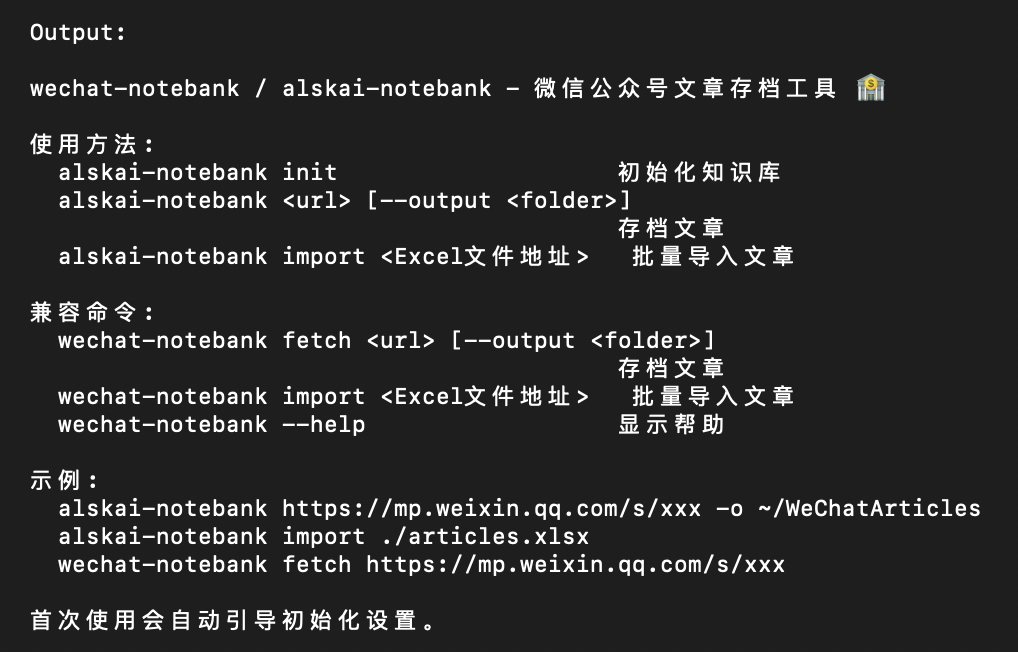
wechat-notebank --help看到 fetch、import、init 这几个命令就说明成功了。
先跑一篇,确认环境没问题
别上来就批量,先用一篇文章测一下。
复制一篇公众号文章链接,跑这个命令:
wechat-notebank fetch https://mp.weixin.qq.com/s/xxxxx --output ~/WeChatArticles--output 后面是你想保存的文件夹,文件夹不存在会自动创建。也可以用短命令 -o。
跑完打开文件夹,你会看到一个 .md 文件,文件名是 2026-03-09-文章标题.md 这种格式。重点来了,前面的日期是文章的真实发布日期,不是你今天抓取的日期。这个细节很重要,知识库的时间线本身就是信息。
打开文件看一眼,里面有 frontmatter:
---title: "文章标题"author: "作者"wechatName: "公众号名称"pubDate: "2026-04-30"sourceUrl: "https://mp.weixin.qq.com/s/xxx"archivedAt: "2026-05-11T07:47:39.535Z"tags: []---
这段元数据以后不管你在 Obsidian、Cursor 还是任何 Markdown 工具里打开,都能知道这篇文章来自哪、什么时候发的、什么时候被你存的。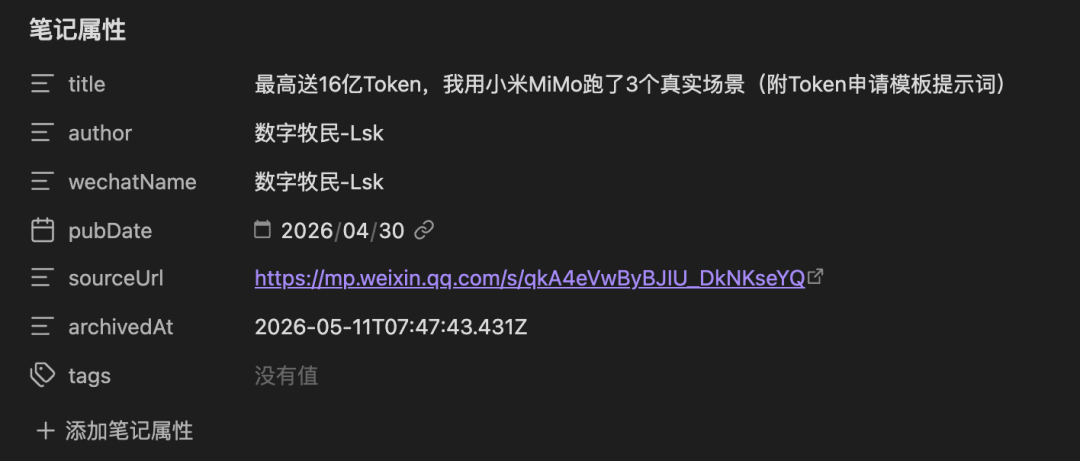
打开文件快速扫一眼,标题、正文、发布日期都对,说明工具在你这台电脑上跑通了。放心往下走。
准备一张 Excel,这才是重头戏
单篇保存只是验证环境,真正解决问题的是批量导入。
你需要一个 .xlsx 文件(用 Numbers 的话先导出成 Excel)。表格长这样:
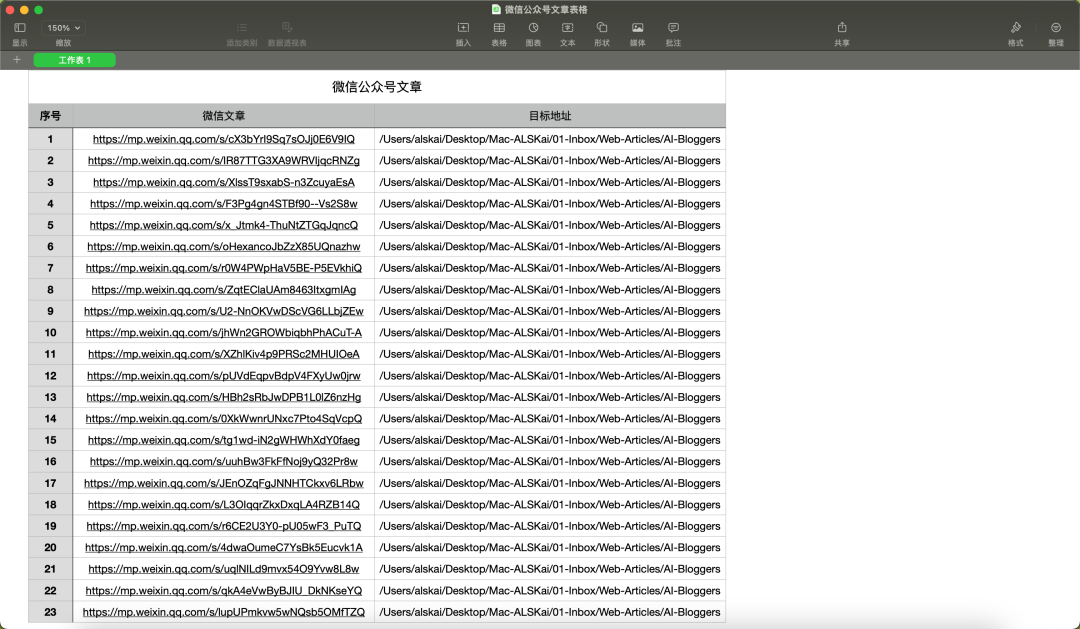
第一列序号,第二列公众号文章链接,第三列保存路径。就这么三列。
这个设计的好处是你可以在第三列按博主或主题分目录。AI 博主的文章放一个文件夹,产品发布放一个文件夹,工具教程放一个文件夹。Excel 就变成了你的临时收集台,看到好文章先填进去,攒够了一次性导入。
(手头链接太多懒得手动填?直接丢给 Claude 或 ChatGPT,说"帮我把这些链接整理成三列表格,第一列序号,第二列链接,第三列文件地址统一用 ~/WeChatArticles/AI-Bloggers",几秒钟搞定)
一条命令,批量导入
表格准备好之后:
wechat-notebank import ./articles.xlsx工具会读第一个工作表,按行处理。三列都完整就抓取,缺任何一列就跳过。
这里有个设计值得说一下,某一行失败不会影响后面的文章。跑完之后终端会告诉你成功几篇、失败几篇、跳过几行。

我踩过一个坑。一开始某一行没抓下来,终端只告诉我"失败 1 篇",没说为什么。这个体验很糟,批量导入最怕的是失败,更怕失败了不知道哪一行出问题。链接失效、页面加载超时、目标路径没权限,都可能。后来我把失败详情补上了,现在每一行失败都会打印行号、序号、链接、保存路径和错误原因。单独修这一行就行,已经成功的文章也不会重复保存。
生成的文件长什么样
批量跑完,你指定的每个文件夹里都会多出一堆 .md 文件。文件名格式是 YYYY-MM-DD-文章标题.md,按发布日期排序,天然就是一条时间线。
文件内容包含文章正文和 frontmatter 元数据。图片链接也会保留(微信用的是懒加载,工具会自动把 data-src 转成正常 src)。
如果你发现文件名有重名,不用担心,工具会自动在后面加 -2、-3,不会覆盖已有文件。
有个细节,文件名里的标题会做清理,只保留中文、字母和数字,最长 20 个字。这是为了避免特殊字符导致文件系统报错。
它还做不到的事
说几个这个工具的限制(目前是限制,看看后期能怎么修)
它需要本机装 Chrome。因为微信公众号页面需要浏览器渲染,没 Chrome 跑不起来。
它目前只从 GitHub 安装。npm 包还没正式发布,可能你看到这篇文章的时候已经发了,但写的时候还没有。
它只保存文章内容,不处理点赞、在看这些互动。我专门试过,这些动作绑微信账号,涉及登录态和风控,强行自动化不稳定。(如果你觉得某篇文章真的好,我建议你保存之前先回原文点个赞,创作者需要反馈,工具不应该把这件事抹掉!多给创作者们关爱💗吧!!!)
还有一个容易忽略的点,.wechat-notebank.json 配置文件是跟着当前目录走的,不是全局的。你在哪个目录下跑 init,配置就写在哪个目录。如果后面 fetch 找不到配置,检查一下是不是切了目录。
你适合用它吗
如果你只是偶尔收藏一篇文章,微信收藏夹够用,没必要折腾。
但如果你长期关注几个公众号博主,想把文章沉淀进 Obsidian、Notion 或本地文件夹;或者你写东西经常需要回看过去读过的材料,不想每次靠记忆翻"不知道在哪"的文章。wechat-notebank 适合你。
尤其是做 AI 写作、产品研究、行业观察的人。这类人最痛的不是没有信息,是信息太多来不及沉淀。这个工具不能帮你判断哪篇文章值得读,但能帮你把"值得保存的文章"放到一个稳定的位置。
项目地址在这里:
https://github.com/Albert-Lsk/wechat-notebank你打算用它存哪几个公众号?评论区说说。「如果对你有用,欢迎关注我,让我们一起用 AI 做点有趣的事。🌿」